
YOLOは「You Only Look Once」の頭文字を取っており、YOLOの著者であるJoseph Redmon氏はモデルに「見るのは一度きり」という意味を付けました。YOLOはその意味の通り、高精度の画像認識用のオープンソースのニューラルネットフレームワークです。今回は画像処理分野で話題のYOLOのv5の環境構築を行っていきたいと思います。
CONTENTS
YOLOv5とは
YOLOというのはもともと”You only live once”「人生一度きり」の頭文字をとったスラングで,これをYOLOの著者であるJoseph Redmon氏は”You Only Look Once”「見るのは一度きり」という風に文字ってモデルを名付けました。
今までにv1〜v5までがリリースされています。v1〜v4まではJoseph Redmonさんが関与しているのですが、v5は関与していないため、vXのネーミングについては賛否があるようです。
- YOLOv1 発表:2016年 5月 製作者:Joseph Redmon
- YOLOv2 発表:2017年12月 製作者:Joseph Redmon
- YOLOv3 発表:2018年 4月 製作者:Joseph Redmon, Ali Farhadi
- YOLOv4 発表:2020年 4月 製作者:Alexey Bochkovskiy
- YOLOv5 発表:2020年 6月 製作者:Glenn Jocher
YOLOのv1〜v3は、Joseph Redmonさんによって作成されました。これに続いて同じくdarknetを活用してAlexey BochkovskiyさんがYOLOv4を作成しました。このv4は、従来のバージョンと比べて、高い平均適合率(AP)と速い処理速度を誇っています。
そして2020年6月に、Glenn JocherさんがPyTorchを使用し、YOLOv4に匹敵する平均適合率(AP)を持ち、推論処理時間がより高速なYOLOv5をリリースしました。このv5はdarknetも使用しておらず、Joseph Redmonさんが関与していないため、vXの名前を名乗るのが正しいのか、また本当にv4から改善されているのか多くの人が疑問を呈しています。
YOLOv5の処理速度と平均適合率(AP)
YOLOv5には、4種類のCOCOモデルが提供されています。COCOの平均適合率が大きい方が精度が上がりますが、その分処理速度は遅くなります。
以下のグラフはYOLOv5の各データセットでのCOCO AP valとGPU Speedの関係を現したグラフです。これをみる限りではYOLOv5mか、YOLOv5l当たりが速度とAPの関係的には使いやすそうですね。
| Model | APval | APtest | AP50 | SpeedGPU | FPSGPU | param | GFLOPS | |
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 37.0 | 37.0 | 56.2 | 2.4ms | 416 | 7.5M | 17.5 | |
| YOLOv5l | 44.3 | 44.3 | 63.2 | 3.4ms | 294 | 21.8M | 52.3 | |
| YOLOv5m | 47.7 | 47.7 | 66.5 | 4.4ms | 227 | 47.8M | 117.2 | |
| YOLOv5x | 49.2 | 49.2 | 67.7 | 6.9ms | 145 | 89.0M | 221.5 | |
| YOLOv5x + TTA | 50.8 | 50.8 | 68.9 | 25.5ms | 39 | 89.0M | 801.0 |
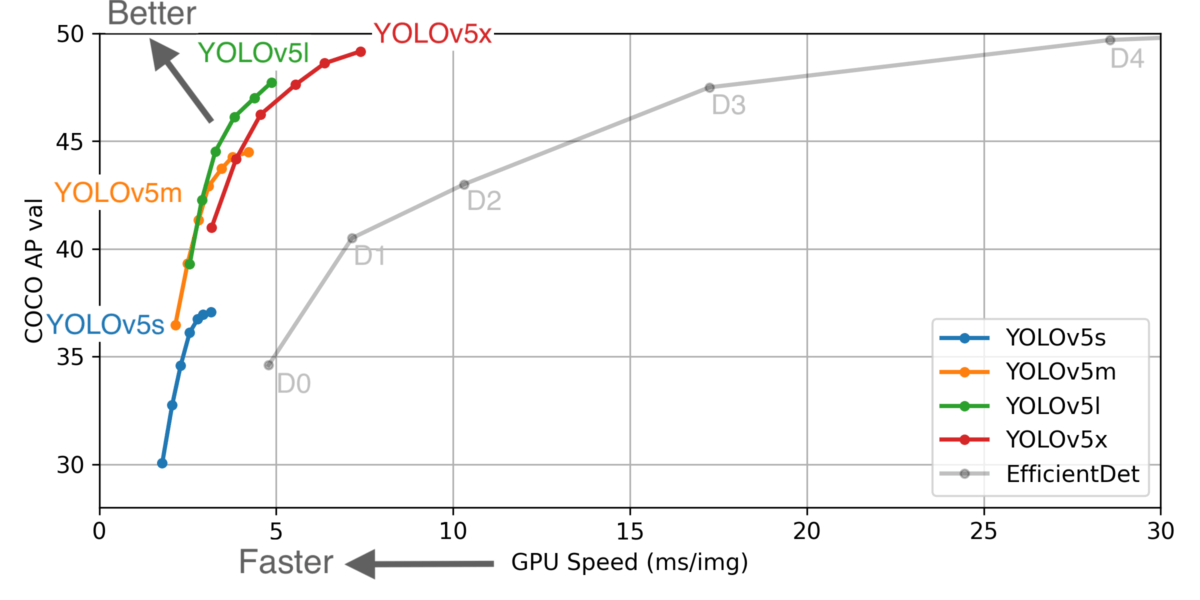
またYOLOv4ではスペック的にAPでは勝っているようですが、同じ速度域ではYOLOv5の方がグラフ上は良さそうですね。
YOLOv5の導入方法
さっそくYOLOv5を導入していきます。私の環境はMacbook Air Intelモデルですね。OSはmacOS Big Sur v11.1となります。
Pythonの仮想環境構築
まずPythonの仮想環境を構築していきたいと思います。まだPythonの環境を構築していない方は先に以下の記事を参考に環境構築をしてください。私は既存のMacのPython環境を使用せず、HomebrewでPython環境を構築しています。

続いて Command + Space でSpotlightを開いて Terminal.app と打ってターミナルを起動します。以下のコマンドをターミナルで入力し、Pythonの仮想環境を構築します。仮想環境はvenvで作成しており、 yolov5 としています。
cd ~/envs
python3 -m venv yolov5
YOLOv5のインストール
YOLOv5をローカルに保存していきます。gitコマンドで落とすため、git環境がない方は以下の記事を参考にgitを導入してください。

こちらも同様にターミナルで以下のコマンドを入力していきます。今回は Projects 以下に yolov5 の環境を作成していきます。
git clone で yolov5 をクローンします。これでYOLOv5のインストールは完了です。
cd ~/Documents/Projects
git clone https://github.com/ultralytics/yolov5.git
Code language: JavaScript (javascript)Pythonのライブラリ追加
次にYOLOv5の実行に必要なPythonのライブラリを追加していきます。PyTorchを使用しているのでその周りのライブラリの追加が必要になります。
先ほど追加したPythonの仮想環境に切り替えして、gitからクローンしてきたフォルダに必要なライブラリのリストのファイル requirements.txt があるので、 pip でインストールします。
umilcl@UMilCL-MacBook-Air Projects % source ~/envs/yolov5/bin/activate
(yolov5) umilcl@UMilCL-MacBook-Air yolov5 % pip install -U -r requirements.txt
Code language: JavaScript (javascript)私はこの際にpipが古いのでアップグレードしろと怒られましたので、 pip install --upgrade pip で最新のpipにすることでエラーはなくなりました。
ここまでくれば、あとはdetect.pyを実行するだけです。
YOLOv5 画像処理の実行
YOLOv5の実行方法は以下の通りです。webカメラで使用する場合は --source 0 、ファイルならそのファイル、ディレクトリやストリームなど様々な形式に対応しています。
python detect.py --source 0 # webcam
file.jpg # image
file.mp4 # video
path/ # directory
path/*.jpg # glob
rtsp://170.93.143.139/rtplive/470011e600ef003a004ee33696235daa # rtsp stream
rtmp://192.168.1.105/live/test # rtmp stream
http://112.50.243.8/PLTV/88888888/224/3221225900/1.m3u8 # http stream
Code language: PHP (php)今回は参考に以下の動画をYOLOv5sで処理した結果を載せています。
元動画へのリンク
ダウンロードしたファイルをyolov5のプロジェクトフォルダ直下に入れて以下のコードを実行します。実行結果のファイルが runs/detect/exp 以下に作成されます。
python detect.py --source video.mp4
Code language: CSS (css)見ていただいてわかるかと思いますが、初期状態でかなりの精度でサッカーボールや人、車、ボトルなどが検知できていることがわかるかと思います。
デフォルトでは、一番軽量なYOLOv5sが使用されます。他のモデルを使用するには --weights yolov5x.pt のように使用するモデルを指定します。
python detect.py --source video.mp4 --weights yolov5x.ptCode language: CSS (css)トレーニング用の教師データ作成と学習実行
続いてアノテーションツールを使用して、アノテーションを付加した教師データを作成していきます。今回使うツールはLabelImgとなります。
Homebrewを使用してインストールしていきます。
brew install qt
brew install libxml2
pip3 install pyqt5 lxml
cd Documents/Projects
git clone https://github.com/tzutalin/labelImg.git
make qt5py3
Code language: PHP (php)インストールが完了したら、以下のコードを実行して画像を選択し、アノテーションを作成していきます。対象の画像の範囲を選択し、ラベルを付けていきます。
今回はメーターを取得したかったので、メーターのアノテーションを作成しています。
python3 labelImg.py
python3 labelImg.py [IMAGE_PATH] [PRE-DEFINED CLASS FILE]
Code language: CSS (css)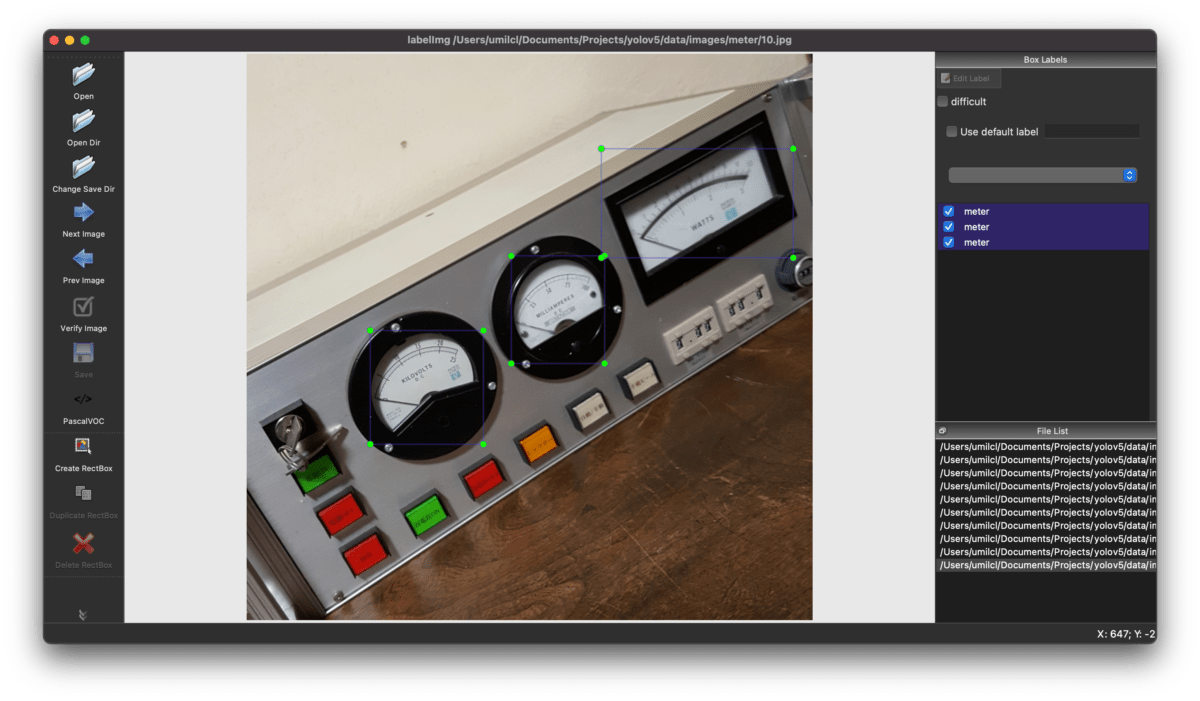
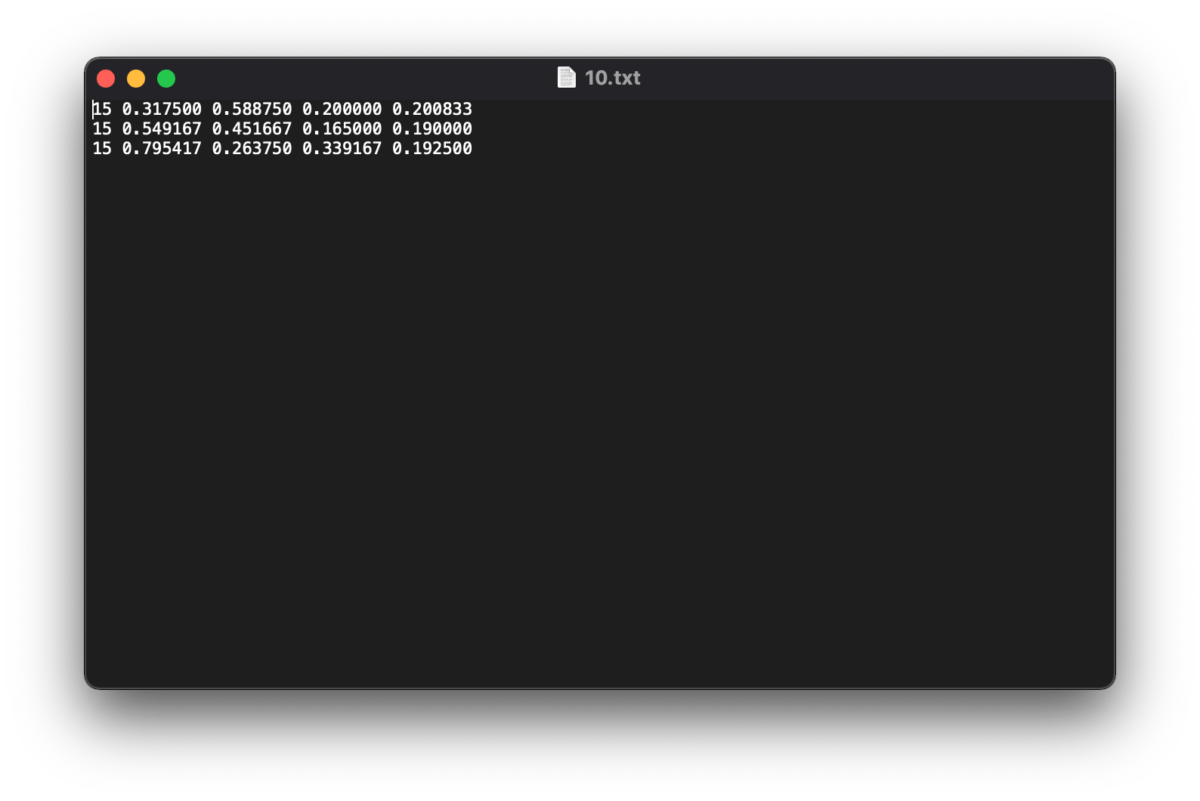
YOLO形式にフォーマットを変更し、保存したデータが以下となります。txt形式で各画像毎に[the class_id, x_center, y_center, width, height]の値が入っています。
またclasses.txtというmeterなどのアノテーションのタグ情報が入ったファイルも作成されます。
このデータを100枚以上作ろうと考えたのですが、どう考えても時間がなかったので、今回は以下のサイトの用意されているデータセットにて学習させました。
工場つながりということで ['head', 'helmet', 'person'] の3つのクラスを持つデータセットで試しました。

学習用のフォルダを Projects/yolov5 以下に作成します。
mkdir trainingtraining以下に dataset.yaml とダウンロードした画像、アノテーションデータの train と test をそれぞれ保存します。また yolov5/model 以下にある yolov5l.yaml などのYOLOモデルのパラメータを保存します。
<strong>dataset.yaml</strong>
# train and val datasets (image directory or *.txt file with image paths)
train: training/train/images
val: training/test/images
# number of classes 今回は3つのクラスのため、3とします。
nc: 3
# class names
names: ['head', 'helmet', 'person']
Code language: YAML (yaml)コピーしてきたyolov5l.yaml のファイルを開いて、 nc: の値をclassの数に合わせて修正します。今回は3となります。
<strong>yolov5l.yaml</strong>
# parameters
<strong>nc: 3 # number of classes
</strong>depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
Code language: YAML (yaml)準備が整ったら、以下の様にコマンドを実行し、トレーニングを開始します。
python3 train.py --batch 16 --epochs 300 --data training/dataset.yaml --cfg training/yolov5l.yaml --weights ''Code language: Bash (bash)学習を開始すると runs/train に学習データが作成されます。

学習が完了するとモデルデータが作成されます。作成されたモデルデータを yolov5 直下に保存し、以下の様にコードを実行します。
これでオリジナルの学習データでの検出が可能となります。
python detect.py --source 0 --weights 作成したモデル.ptCode language: CSS (css)私は忘れていましたが、 tensorboard で実行結果を確認したい人は事前に起動しておいて、途中で別のターミナルから実行中の結果をチェックすると学習状態を確認することができます。
load_ext tensorboard //起動
tensorboard --logdir runs //確認Code language: JavaScript (javascript)まとめ
YOLOv5を使うと結構簡単に自分の検知したいものの位置を取得することができる様になります。画像のどの部分かわかると、あとは他の方法を組み合わせて様々なことが可能になります。
こんなに簡単にそこらへんの人でも画像処理ができる様になるソフトウェアを提供してくれているJoseph Redmonさんからの流れに感謝です。
また今年はこれで最後の更新となります。今年からブログを始めましたが、意外と楽しみながら更新することができており、また来年もしっかり続けていきたいと思います。
今年はコロナとブログのおかげで趣味を楽しめる一年でした。来年はどんな一年になるでしょうか?
それでは皆さん良いお年を!

{kind=link}